これは、なにをしたくて書いたもの?
テキスト埋め込みについていろいろ試していて、どんなモデルがあるのか知らないといけないなと思ったところ、MTEBという
ベンチマークの存在を知ったのでメモしておこうかなと。
MTEB(Massive Text Embedding Benchmark)
Massive Text Embedding Benchmark、略してMTEBはテキスト埋め込みのベンチマークです。
[2210.07316] MTEB: Massive Text Embedding Benchmark
Hugging Faceのブログに、MTEBの紹介があります。
MTEB: Massive Text Embedding Benchmark
MTEBの説明自体はこちらの記述を読んだ方がいいでしょうね。
[2210.07316] MTEB: Massive Text Embedding Benchmark
テキスト埋め込みは、以下のような様々なタスクで用いられます。
あるタスクで効果を発揮したモデルが、別のタスクでも有用なのかは未知数です。そして様々なモデルが評価なしに生み出されており、
テキスト埋め込みという分野の進捗を追跡することが困難になったため作られたもののようです。
MTEBは58のデータセットと112の言語をカバーする8つのタスク、33のベンチマークで構成されています。
8つのタスクというのは、以下になります。
- クラスタリング(Clustering)
- 分類(Classification)
- ペア分類(Pair Classification)
- テキストマイニング(Bitext Mining)
- リランキング(Reranking)
- 検索(Retrieval)
- 意味類似度(STS:Semantic Textual Similarity)
- 要約(Summarization)
様々なモデルに対するベンチマークの結果は、リーダーボード上で公開されています。
MTEB Leaderboard - a Hugging Face Space by mteb
Hugging Faceのブログによると、紫色のものは多言語のデータセットだそうです。
Overview of tasks and datasets in MTEB. Multilingual datasets are marked with a purple shade.
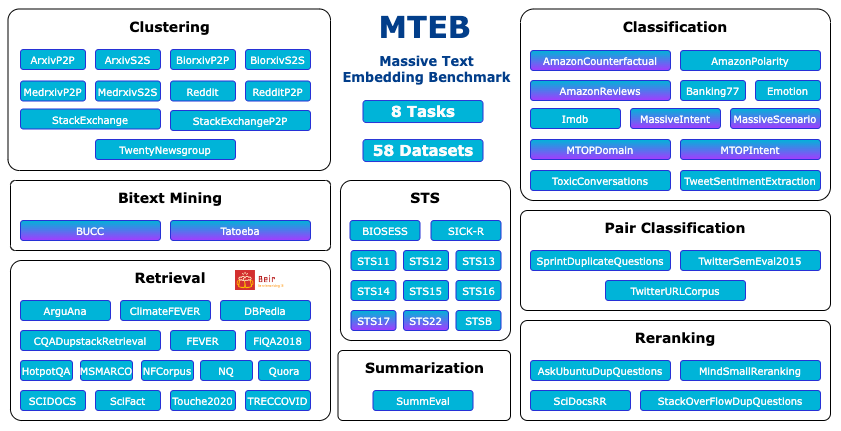
MTEB: Massive Text Embedding Benchmark
個人的には、意味的類似度(STS)と検索(Retrieval)が気になるところです。
GitHub - embeddings-benchmark/mteb: MTEB: Massive Text Embedding Benchmark
データセットを見たところ、日本語が入っているのは分類(Classification)のみのようですが…。
意味的類似度といえば、JGLUEにもJSTSがあったので評価としてはこちらも併用するとよいのかもしれません。
GitHub - yahoojapan/JGLUE: JGLUE: Japanese General Language Understanding Evaluation
いずれにしても、MTEBおよびリーダーボードの存在は現状の埋め込みモデルの把握にはとても良さそうですね。
覚えておきましょう。
気になるモデル
OpenAIのテキスト埋め込みモデルはtext-embedding-ada-002ですが、MTEBではこれを上回るものがありますね。
ベンチマークのスコア的にも、調べたみたところの評判でも、以下のintfloatのe5(多言語版)が良さそうです。
intfloat/multilingual-e5-large · Hugging Face
intfloat/multilingual-e5-base · Hugging Face
intfloat/multilingual-e5-small · Hugging Face
そのうち試してみたいなと思います。